数据库操作
创建数据库两种方式
1 | create database testdb charset utf8; |
查看所有数据库以及数据库的设置
1 | show databases; |
进入(使用)数据库
1 | use testdb; |
删除数据库的两种方式
1 | drop database testdb; |
数据库名字不可以修改,数据库的修改仅限库选项: 字符集和校对集(校对集依赖字符集)
修改字符集和校对集合
1 | alter database testdb character set utf8mb4 collate utf8mb4_unicode_ci. |
字符集(Character)决定了如何将字符存储在数据库中。不同的字符集占用的存储空间不同,支持的字符范围也不同
校对集(Collation)决定了字符的排序规则和比较规则。utf8mb4_general_ci 是一个常用的排序规则,它不区分大小写。如果未指定排序规则,MySQL 会使用该字符集的默认排序规则。
utf8、utf8mb4、utf8mb4_unicode_ci的关系
在 MySQL 8.0 以前,utf8 是 utf8mb3 的别名,它只支持最多 3 个字节的 UTF - 8 编码字符,无法存储表情符号等 4 字节字符。从 MySQL 8.0 开始,默认的字符集从 latin1 更改为 utf8mb4,此时,utf8 这一名称实际上对应的还是 utf8mb3,但官方明确推荐使用 utf8mb4,并且未来可能会将 utf8 重新定义为 utf8mb4。因此,在MySQL8.0中创建数据库时,使用 utf8mb4 是更明确和推荐的做法。
utf8mb4 是 utf8 的超集,意味着 utf8 能表示的字符 utf8mb4 都能表示,但 utf8mb4 还能表示一些 utf8 无法表示的字符,比如表情符号等。
utf8 最多使用 3 个字节来表示一个字符,而 utf8mb4 最多使用 4 个字节,因此 utf8mb4 需要更多的存储空间。校对集utf8mb4_general_ci 是一个常用的排序规则,它不区分大小写。如果未指定排序规则,MySQL 会使用该字符集的默认排序规则。
表的操作
创建表
1 | 字段+数据类型+其他要求 |
删除表
drop table students,...;
进数据库前不能使用命令show tables
查看表
1 | show tables; |
模糊查询
show tables like 's%';
查看表结构 \g横向,默认设置;\G纵向;注意后面不能加分号(字段修饰横向/纵向显示)
1 | desc students;desc students\G |
查看表结构创建语句
1 | show create table students; |
复制表结构
1 | create table stu_bak like students; |
复制表数据
1 | insert into stu_bak select * from students; |
复制表结构同时备份数据
1 | create table stu_bak2 select * from students; |
rename修改表名
1 | alter table 旧表名 rename 新表名; |
字段操作
修改字段名:alter...change...
修改字段修饰:alter...modify...
添加字段:add
删除字段:drop
修改字段名用change:
Alter table +表名+change+旧字段+新字段+新字段修饰;
1 | alter table students change username name varchar(100) not null default ''; |
修改字段修饰用modify :
1 | alter table students modify name varchar(50) not null default '' comment '姓名'; |
添加字段 用add (after/before):
1 | alter table students add time int not null default 0 after money; |
删除字段drop:
1 | alter table students drop time; |
主键操作
添加主键自增:先添加主键 ,再添加自增
1 | alter table students add primary key(id); |
删除主键:先删除自增,再删除主键
1 | alter table students modify id int; |
常用数据类型与修饰
decimal(5,2):浮点型,指一共五位数字,其中两位小数,整数3位多了报错,小数多了四舍五入。相比于float,double类型,decimal类型属于精确类型,不会丢失精度,所以只要涉及到金钱,财务相关的数据,对应的类型一定要选择decimal。
1 | Decimal(18,9),18这个数代表最长可以到18位,而9这个数字表示小数点后面有9位数字,那么18-9=9,也就得出了整数位可以有9位。 |
enum:枚举,单选型,用于存储单一值
1 | alter table students add gender1 ENUM('男', '女') |
set:集合类型,多选型,用于存储多个值
1 | alter table students add hobby1 set('羽毛球', '篮球','乒乓球'); |
char(6) :定长,效率高,最多存储6个字符。即无论存储的字符串实际长度如何,它都会使用定义时指定的字符数来存储数据,不足部分会用空格填充。
varchar(30) :变长,省空间。即它只占用必要的空间来存储实际的字符串长度,并且在末尾存储一个长度字节(对于长度小于或等于255的字符串)或两个长度字节(对于长度大于255的字符串)。
Int(10):指定zerofill前导0填充,不足10位时,以0填充,超过则正常显示,不做宽度限制。无论int(9)还是int(3),都是占用四个字节的空间
unique:唯一约束
primary key:主键,一个表最多只能有一个主键,主键列中不能null 0 重复值
auto_increment:自增
unsigned:非负修饰(设置前导零会自动设置上)
not null:不为空
default :默认值
如果是char或varchar类型,length可以小于字段规定长度。
Mysql 数据类型:
数值类型:
MySQL 支持所有标准 SQL 数值数据类型。
这些类型包括严格数值数据类型( INTEGER、SMALLINT、DECIMAL 和 NUMERIC ),以及近似数值数据类型( FLOAT、REAL 和 DOUBLE PRECISION )。
关键字 INT 是 INTEGER 的同义词,关键字 DEC 是 DECIMAL 的同义词。
BIT数据类型保存位字段值,并且支持 MyISAM、MEMORY、InnoDB 和 BDB 表。
作为 SQL 标准的扩展,MySQL 也支持整数类型 TINYINT、MEDIUMINT 和 BIGINT
| 数据类型 | 大小 | 范围(无符号) | 范围(有符号) | 描 述 |
|---|---|---|---|---|
| TINYINT(size) | 1字节 | (0,255) | (-125,127) | 小整数值 |
| SMALLINT(size) | 2字节 | (0,65535) | (-32768,32767) | 大整数值,size 默认为9 |
| MEDIUMINT(size) | 3字节 | (0,16777215) | (-8388608,8388607) | 大整数值,size 默认为 9 |
| INT(size)或INTEGER | 4字节 | (0,4294967295) | (-2147483648,2147483647) | 大整数值,size 默认为 11 |
| BIGINT(size) | 8字节 | (0,18446744073709551615) | (-9223372036854775808,9223372036854775807) | 极大整数值,size 默认为 20 |
| FLOAT(size,d) | 4字节 | 0,(1.175 494 351 E-38,3.402 823 466 E+38) | (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) | 单精度浮点数,size 参数中规定显示最大位数,d 参数中规定小数点右侧的最大位数 |
| DOUBLE(size,d) | 8字节 | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | (-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度浮点数,size 参数中规定显示最大位数,d 参数中规定小数点右侧的最大位数 |
| DECIMAL(M,D) | 默认M=10,D=0 | 依赖于M和D的值 | 依赖于M和D的值 | M 为精度;D为保留的小数位数 |
以上的 size 代表的并不是存储在数据库中的具体的长度,如 int(4) 并不是只能存储4个长度的数字。
实际上int(size)所占多少存储空间并无任何关系。int(3)、int(4)、int(8) 在磁盘上都是占用 4 btyes 的存储空间。就是在显示给用户的方式有点不同外,int(M) 跟 int 数据类型是相同的。
例如:
1 | int的值为10 (指定zerofill) |
字符串类型:
指 CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM 和 SET
| 数据类型 | 大小 | 描述 |
|---|---|---|
| CHAR(size) | 0-255字节 | 定长字符串,保存固定长度的字符串(可包含字母、数字以及特殊字符),括号中指定字符串的长度,最多 255 个字符(字母)。 |
| VARCHAR(size) | 0-65535 字节 | 变长字符串,保存可变长度的字符串(可包含字母、数字以及特殊字符)。在括号中指定字符串的最大长度。最多 65535 个字符。 |
| TINYTEXT | 0-255字节 | 短文本字符串,存放最大长度为 255 个字符的字符串。 |
| TEXT | 0-65 535字节 | 长文本数据,存放最大长度为 65,535 个字符的字符串。 |
| TINYBLOB | 0-255字节 | 不超过 255 个字符的二进制字符串 |
| BLOB | 0-65 535字节 | 二进制形式的长文本数据,用于 BLOBs(Binary Large OBjects)。存放最多 65,535 字节的数据。 |
| MEDIUMTEXT | 0-16 777 215字节 | 中等长度文本数据,存放最大长度为 16,777,215 个字符的字符串。 |
| MEDIUMBLOB | 0-16 777 215字节 | 二进制形式的中等长度文本数据,用于 BLOBs(Binary Large OBjects)。存放最多 16,777,215 字节的数据。 |
| LONGTEXT | 0-4 294 967 295字节 | 极大文本数据,存放最大长度为 4,294,967,295 个字符的字符串。 |
| LONGBLOB | 0-4 294 967 295字节 | 二进制形式的极大文本数据,用于 BLOBs (Binary Large OBjects)。存放最多 4,294,967,295 字节的数据。 |
| ENUM(x,y,z,etc.) | - | 允许您输入可能值的列表。可以在 ENUM 列表中列出最大 65535 个值。如果列表中不存在插入的值,则插入空值。**注:**这些值是按照您输入的顺序排序的。 |
| SET | - | 与 ENUM 类似,不同的是,SET 最多只能包含 64 个列表项且 SET 可存储一个以上的选择。 |
CHAR 和 VARCHAR 类型类似,但它们保存和检索的方式不同。它们的最大长度和是否尾部空格被保留等方面也不同。在存储或检索过程中不进行大小写转换。
BINARY 和 VARBINARY 类似于 CHAR 和 VARCHAR,不同的是它们包含二进制字符串而不是非二进制字符串。也就是说,它们包含字节字符串而不是字符字符串。这说明它们没有字符集,并且排序和比较基于列值字节的数值。
BLOB 是一个二进制大对象,可以容纳可变数量的数据,可以存储图片,音视频等文件。有 4 种 BLOB 类型,它们只是可容纳值的最大长度不同。
1 | TINYBLOB:大小:0 - 255字节,用途:短文本二进制字符串 |
数据库并不适合直接存储图片,如果有大量存储图片的需求,请使用对象存储或文件存储,数据库中可以存储图片路径来调用。
TEXT类型同 char、varchar 类似,都可用于存储字符串,一般情况下,遇到存储长文本字符串的需求时可以考虑使用 text 类型。按照可存储大小区分,有 4 种 类型:
1 | TINYTEXT:大小:0 - 255字节,用途:一般文本字符串 |
不过在日常场景中,存储字符串还是尽量用 varchar ,只有要存储长文本数据时,可以使用 text 类型。
对比 varchar ,text 类型有以下特点
1 | - text 类型无须指定长度。 |
text存储字节,varchar存储字符。
数据库规范中一般不推荐使用 blob 及 text 类型,但由于一些历史遗留问题或是某些场景下,还是会用到这两类数据类型的。
存储长文本为什么用text,而不是varchar?
-
长度限制,
VARCHAR类型的最大长度是 65,535 字符。如果你需要存储超过这个长度的文本,VARCHAR就不够用了。 -
存储效率,
VARCHAR是为可变长度的字符串设计的,它存储时会包含长度信息,这使得它在存储长度变化不大的字符串时非常高效。长度信息,额外需要占用1-2个字节的存储开销。TEXT类型不需要存储长度信息,因为它们是固定长度的字段(在定义上),这使得它们在存储大量长文本时更加高效。无额外占用字节的存储开销。 -
性能,
对于非常长的文本,
TEXT类型通常比VARCHAR更有效率,因为它们在存储和检索时的开销更小。VARCHAR在处理短到中等长度的字符串时性能更好,因为它们存储和检索的速度更快。 -
功能特性,
TEXT类型字段支持一些VARCHAR字段不支持的特性,比如全文索引,这在需要进行文本搜索的场景中非常有用。
日期时间类型:
表示时间值的日期和时间类型为 DATETIME、DATE、TIMESTAMP、TIME 和 YEAR。
每个时间类型有一个有效值范围和一个"零"值,当指定不合法的 MySQL 不能表示的值时使用"零"值。
TIMESTAMP 类型有专有的自动更新特性。
| 数据类型 | 大小(字节) | 范围 | 格式 | 描述 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 日期和时间的组合 |
| TIMESTAMP | 4 | '1970-01-01 00:00:01’UTC/'2038-01-09 03:14:07’UTC | YYYY-MM-DD HH:MM:SS | 时间戳,使用 Unix 纪元(‘1970-01-01 00:00:00’ UTC) 至今的秒数来存储。 |
| TIME | 3 | ‘-838:59:59’/‘838:59:59’ | HH:MM:SS | 时间 |
| YEAR | 1 | 1901/2155 | YYYY | 2 位或 4 位格式的年份值。4 位格式所允许的值:1901 到 2155。2 位格式所允许的值:70 到 69,表示从 1970 到 2069。 |
即便 DATETIME 和 TIMESTAMP 返回相同的格式,它们的工作方式很不同。在 INSERT 或 UPDATE 查询中,TIMESTAMP 自动把自身设置为当前的日期和时间。TIMESTAMP 也接受不同的格式,比如 YYYYMMDDHHMMSS、YYMMDDHHMMSS、YYYYMMDD 或 YYMMDD。
数据操作
别名设置,left(),mid(),right(),count(),year(),max(),avg(),sum()函数,if(条件,成立反值,不成立反值)
显示表所有数据
1 | select * from students; |
在字段中查找set类型数据
find_in_set(s1,s2):字段s2的元素中逗号需得是英文",",返回 字符串s1 在 字段s2 中的位置(位置的索引从1开始),如果没有找到,则返回0。如果 s1 或 s2 为 NULL,也将返回 NULL。
1 | 在表students中筛选出字段hobby中包含“篮球”的数据 |
WHERE 子句后面跟的是一个条件表达式,这个表达式的结果会被当作布尔值来处理。FIND_IN_SET('篮球', hobby) 这个函数调用会返回一个整数值。
连接字符串concat
1 | select concat(username,'-',age) from students; |
distinct去重相同数据,后面数据和前面数据合并为一个数据
1 | select distinct sex from students; |
if表达式 i作为if(条件,成立反值,不成立反值)的字段名(别名),显示大于小于
1 | select age,if(age>30,'大于30','小于等于30') i from students; |
order排序 desc 降序 asc升序 默认升序可以省略,有重复age时可以用到
1 | select * from students order by age desc,id desc; |
随机获取3个数据
1 | select * from students order by rand() limit 3; |
解析:
-
ORDER BY RAND() :使用 ORDER BY RAND() 时,MySQL 会为结果集中的每一行生成一个随机数,并基于这个随机数对整个结果集进行排序。排序后,LIMIT 3 子句限制结果集只返回排序后的前3条记录.
-
LIMIT offset, number:
offset 可选参数,默认为0,是整数,表示在开始返回数据之前要跳过的记录数(从0开始计数)。
number 是一个整数,表示在跳过 offset 条记录后返回的结果集的最大行数。
例如,LIMIT 5, 10 会跳过前5条记录,然后返回接下来的10条记录。
1 | rand([seed])可选,如果指定了seed,则返回可重复的随机数序列。如果未指定种子,则返回完全随机的数字,即生成一个随机浮点数值,范围在 0 到 1 之间(不包括 1)。 |
年龄在10-55之间的同学。 between… and…
1 | select * from students where age between 10 and 55; |
查询年龄在23,34,45岁的同学。in(xx,xx,xx)
1 | select * from students where age in (23,34,45); |
字符串截取 left(str,length),mid(str,pos,len),right(str,length)
截取左边开始的2个字符
1 | select left(username,2) from students; |
截取左边第2个字开始的1个字符长度。
1 | select mid(username,2,1) from students; |
模糊查询like
1 | select * from students where hobby like '%羽毛球%'; |
as+别名:查询结果字段显示别名,as可以省略
1 | select username as u,age as a from students; |
获得所有人出生年份
1 | select year(birthday) from students; |
查看班级有多少男同学
1 | select count(*) from students where sex='男'; |
max()最大,sum()求和,avg()求平均值
1 | select max(age) from students; |
男生有多少人
1 | select sex,count(*) from students where sex='男'; |
插入1条数据
1 | insert into students set age=18,money=100; |
插入多条数据:若省略字段名,则默认所有字段
1 | insert into students (username,age,sex) values ('超人',18,'男'),('葫芦娃',18,'男')...; |
更新数据必须要有主键 ,即主键id,否则视为插入数据
1 | replace into students (id,username,age,sex) values (32,'超人复仇者联盟222',18,'男') |
update:
1 | //更新多条数据的特定字段:所有男变为女 |
replace into 与 update的区别:
REPLACE INTO 和 UPDATE 都是在数据库中更新数据的操作,但REPLACE INTO语句首先尝试插入一条新记录,如果已存在具有相同主键(或唯一键)的记录,则先删除旧记录,然后再插入新记录。 而 UPDATE 语句仅更新现有记录的某些列,不会删除或重新插入记录。
删除数据
delete from 表名 条件
1 | delete from students where id=19; |
清空所有数据,让id重新从1开始
1 | truncate students; |
显示警告:
1 | show warnings; |
一对一关联
1 | select * from city; |
根据MySQL的设置,默认接受使用单引号或双引号来表示字符串。
将上面两句以子查询的方式合并一句
1 | select * from code where id=(select code_id from city where city_name='北京'); |
on和where后面所跟的条件不同:
select+查询字段+from+查询表+join+关联表+on+关联条件+where+筛选条件
1 | select city_name,code_name from city join code as c on code_id=c.id where city_name='北京'; |
表别名或字段别名,关键字“as”可以省略
一对多关联
外键对应的表是主表
多表需添加外键(XX_id)指向主表 ,例如:班级和学生,是一对多关系,学生表students表添加外键class_id,指向班级表class
1 | select s.name from class c join students s on c.id=s.class_id where c.class_name = "一班"; |
张三的同班同学(自关联)
1 | select s1.name ,s2.name from students s1 join students s2 on s1.class_id=s2.class_id where s2.name='张三' and s1.name!='张三'; |
多对多关联
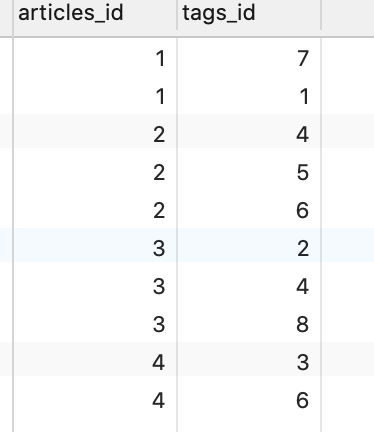
多对多关联需添加第三张表作为中间表,中间表至少包含两个字段,这两个字段分别作为外键,指向各自一方的主键。例如以下是articles与tags是多对多关系,添加中间表articles_tags,其中字段分别指向两表
文章表articles
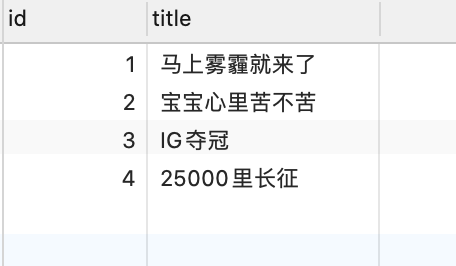
中间表articles_tags
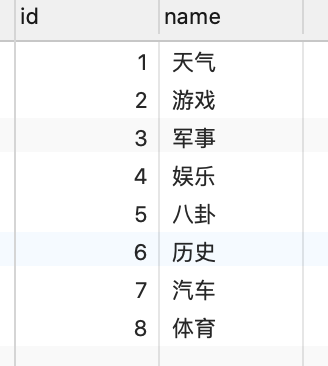
标签表 tags
给每篇文章计数标签
1 | select a.title,count(*) from articles a join articles_tags at on a.id=at.articles_id group by a.title; |
「马上雾霾就来了」文章有哪些标签
1 | select a.title,t.name from articles a join articles_tags at on a.id=at.articles_id join tags t on at.tags_id=t.id where a.title='马上雾霾就来了'; |
其他
select now(); 获得当前日期时间
顺序:where—group by having—order by—limit
students表id>4且年龄最小的女性
有误sql句子:
1 | select * from students where id>4 group by gender having gender='女' order by age limit 1; |
//HAVING 子句通常用于对分组后的结果再处理(在分组后的结果基础上再过滤)。这个条件实际上不会按预期工作,因为group by按gender分组后,无需having再处理,每个分组内的 gender 值已经是确定的。
正确句子:
1 | SELECT * FROM students WHERE id > 4 AND gender = '女' ORDER BY age LIMIT 1; |
HAVING的正确使用:
1 | SELECT salesperson, SUM(amount) AS total_sales |
使用关键字 需加上"``"
1 | create database `databases`; |
查看服务器识别的字符集
1 | show charset; |
MySQL服务器默认的跟客户端打交道的字符集
1 | show variables like 'character_set%'; |
查看MySQL中的存储过程和函数状态
1 | SHOW PROCEDURE STATUS LIKE 'insert_%'\G |
查看设置的过程
1 | SHOW CREATE PROCEDURE insert_d(过程名)\G |
MySQL在windows下是不区分大小写的,将script文件导入MySQL后表名也会自动转化为小写。但再将数据库导出放到linux服务器中使用时就报错了,因为在linux下,表名区分大小写而找不到表,即大小写敏感。可以在linux下更改MySQL的设置使其也不区分大小写,反之要使得在windows下大小写敏感,相应的更改windows中MySQL的设置就行了。